Documentation Index
Fetch the complete documentation index at: https://moengage-crashes-in-debug-feedback.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Early AccessThis is an Early Access feature. To enable it for your account, please contact your MoEngage Customer Success Manager (CSM) or the Support team.
Overview
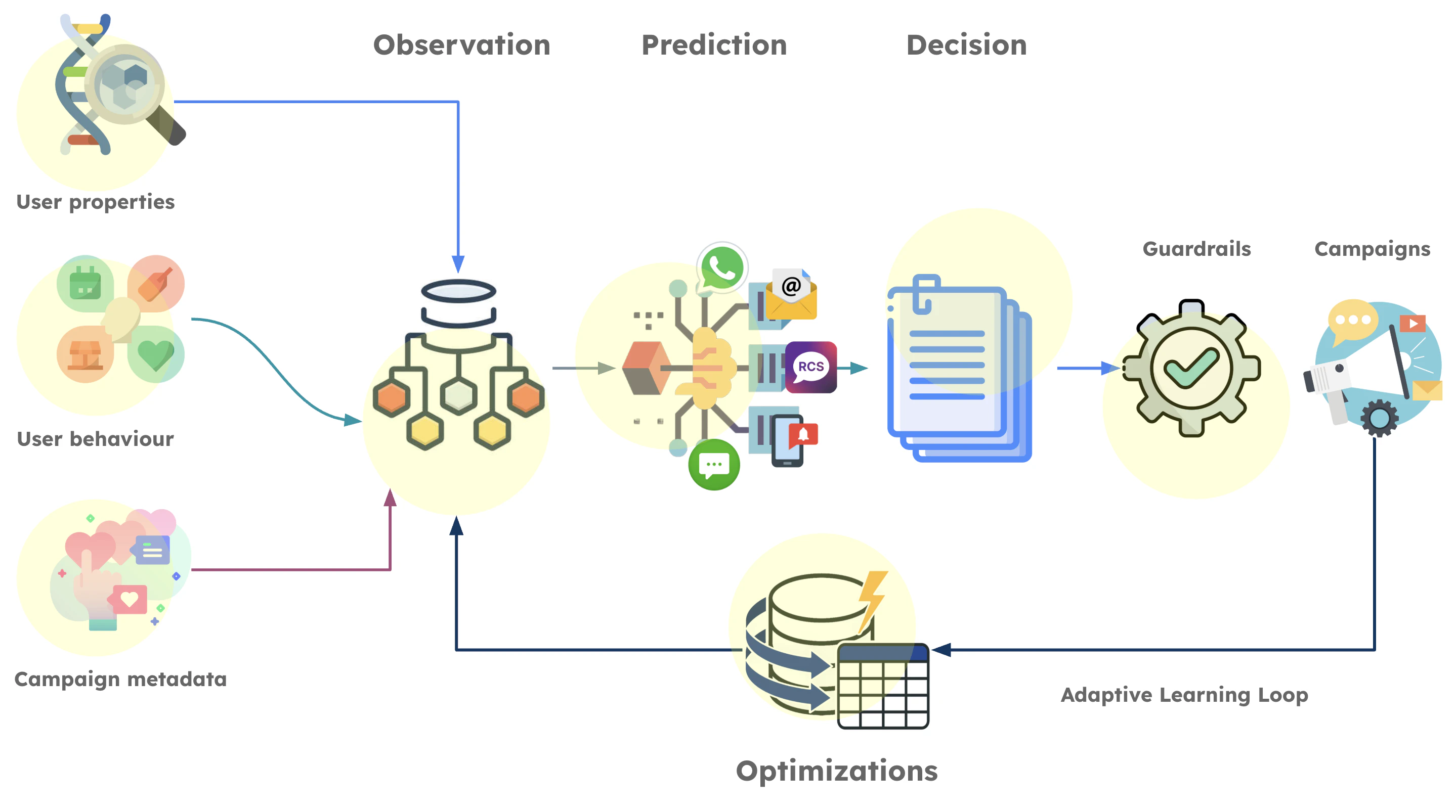
The Campaign Decisioning Agent is a self-learning orchestration system built on a Predict-then-Decide framework. It analyzes user profile, behavioral, and interaction data, calculates the probability of reward for every eligible campaign, and selects the option most likely to maximize your defined business objective. Unlike a standard “if-then” based rule setup, which gets stale over time, the agent does not execute rules. It updates its own decision-making model based on what actually happens after each delivery — reinforcing what works and deprioritizing what doesn’t.Agent Components
To function effectively, every agent is built upon the following foundational pillars:- The reward: Every agent uses a Composite Reward Function, which serves as the mathematical definition of success for the agent. It assigns a weighted value to each reward event you classify, producing a single score the agent optimizes toward. You define which events are positive (e.g., purchases, clicks) and which are negative (e.g., unsubscribes, uninstalls). The agent learns to maximize the net positive value of these events over each user’s lifetime.
- Guardrails: While the AI operates autonomously, you provide the constraints it must operate within: the target audience, frequency caps, allowed exploration bandwidth, and control group size. The agent optimizes continuously — but only within these boundaries. Guardrails are how you enforce brand safety and protect the user experience.
Decisioning Intelligence Process
When a user becomes eligible for engagement, the agent’s intelligence engine executes the following process:- Observation: The agent gathers the current state of the user to model intent. It analyzes user properties, aggregated behavior (such as purchase frequency and average order value), and the semantic similarity of campaigns. This calculates how closely campaign content aligns with the evolving interests of both the individual and their lookalike audiences.
- Prediction: Leveraging a Multi-Task Learning architecture, the agent forecasts multiple outcomes in parallel. It moves beyond simple binary triggers to calculate individual probabilities of reward events for positive engagement, potential churn, or fatigue.
- Decision: The agent ranks all campaign options by aggregating the probabilities of target reward events into a single Composite Reward Score. It evaluates each option against the current context to identify top candidate campaigns that adhere to your guardrails. This phase also runs strategic exploration, particularly for “cold” users or new assets, allowing the agent to discover new strategies rather than relying solely on historical patterns.
| Event Classification | Weight |
|---|---|
| Very Good | +1.0 |
| Good | +0.5 |
| Bad | −0.5 |
| Very Bad | −1.0 |
Purchase Completed= Very Good (+1.0)Product Viewed= Good (+0.5)Push Notification Unsubscribed= Very Bad (−1.0)
- P(Purchase Completed) = 0.12
- P(Product Viewed) = 0.45
- P(Push Notification Unsubscribed) = 0.03
(0.12 × 1.0) + (0.45 × 0.5) + (0.03 × −1.0) = 0.12 + 0.225 − 0.03 = 0.315
The agent calculates this score for every eligible campaign and selects the highest-scoring option within your guardrails. If Campaign C scores 0.41 for User A, Campaign C is delivered instead.
This phase also runs strategic exploration — intentionally testing lower-probability options for a defined proportion of traffic. This prevents the agent from converging on a local optimum and ensures it continues discovering new effective strategies as user behavior evolves.
-
Optimization: The agent closes the loop by gathering outcomes from real-world execution. This feedback reinforces result-yielding strategies and pivots away from underperforming ones, ensuring the agent continuously adapts its logic to maximize ROI.
Decision-Making Mechanisms
The agent learns and adapts over time using the following mechanisms:- Reinforcement learning: Unlike static models that require manual retraining, the agent learns through reinforcement. Every user interaction — click, purchase, dismissal, unsubscribe — is a feedback signal. The agent uses Incremental Training to update its parameters in real time. If a decision leads to a reward, the strategy is reinforced; if not, the agent adjusts immediately.
- Contextual Multi-Armed Bandits (CMAB): The decision-making core is powered by CMAB. Unlike standard models that predict a fixed outcome, CMAB serves as an adaptive policy engine that maps specific user context to the next-best decision. This prevents the agent from becoming stuck in a local optimum and ensures it automatically adapts as user behavior and market trends drift. CMAB optimizes its policies by managing the following trade-off:
- Exploitation: The agent uses what it knows to be the best-performing message for a user based on their current profile.
- Exploration: The agent intentionally tests “wildcard” options on small subsets of traffic to discover new patterns. This solves the “cold start” problem for new campaigns.
Cold Start Behavior
Human Roles in Agent Steering
The human role is critical in providing the strategic inputs that steer the AI, as well as exercising judgment where needed.- Strategic intent: You can define the AI’s high-level objectives and translate complex business priorities, such as balancing acquisition volume with long-term margins, into the mathematical rewards the agent uses to learn.
- Governance: You can establish the non-negotiable boundaries—from message frequency and quiet hours to strict brand safety to ensure the AI honors the user relationship. This ensures that AI speed and scale do not compromise brand integrity.
- Creative diversity and judgment: While the agent handles scale, it relies on you to establish the core creative vision and human resonance. By providing a diverse set of creative messages, you allow the AI to strategically map the right value proposition to the users most likely to engage.